Research
What is an "ideal" response to a prompt? How do you quantify how "ideal" it is? Success depended not only on whether a pipeline worked, but on the strategy used to build it and the context provided to the user.
To focus the PoC, we tested assumptions around user expectations of AI capability, acceptable failure modes, and differences between less-technical users and power users. Engineers built a constrained MVP model and we tested it with internal users across experience levels. We delivered instructions as broad, multi-step goals based on real use cases from our User Support and Enablement Slack channels.

To quantify performance without over-indexing on raw metrics, participants assigned letter grades (A+ to F) to the Copilot’s overall performance, along with the minimum grade they would consider acceptable for a GA release, and adjustments required to reach an A. These grades were paired with qualitative feedback and comparisons to other AI tools participants used in their daily work (e.g., ChatGPT, Gemini, Claude).
After iterative refinement, the same evaluation framework was applied with real customers in our Product Preview group to validate findings prior to general availability.

Key Refinements for Success
Research findings allowed us to prioritize four areas that significantly improved model training and output quality:
Allow users to manually switch between Build and Ask modes. Providing the user explicit control increased trust and confidence, helping mitigate moments when model output underperformed.
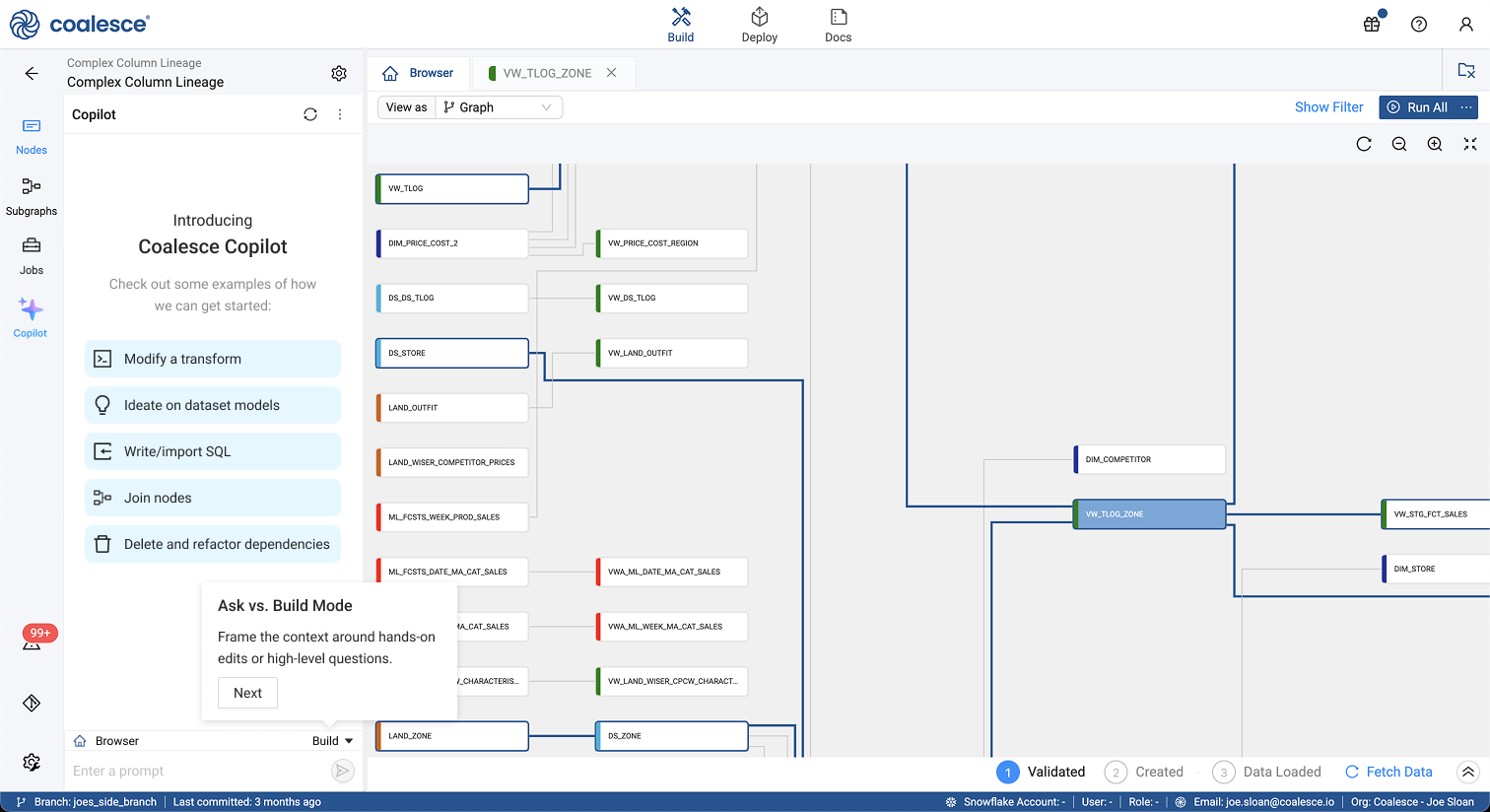
Keep language non-technical, even when the underlying solution is complex. Users who want deeper technical detail reliably ask for it, while simpler explanations improve comprehension and adoption for everyone else.
Use explanations to accelerate learning. Informative reasoning helped less-technical users achieve higher-quality results within just a few prompts.
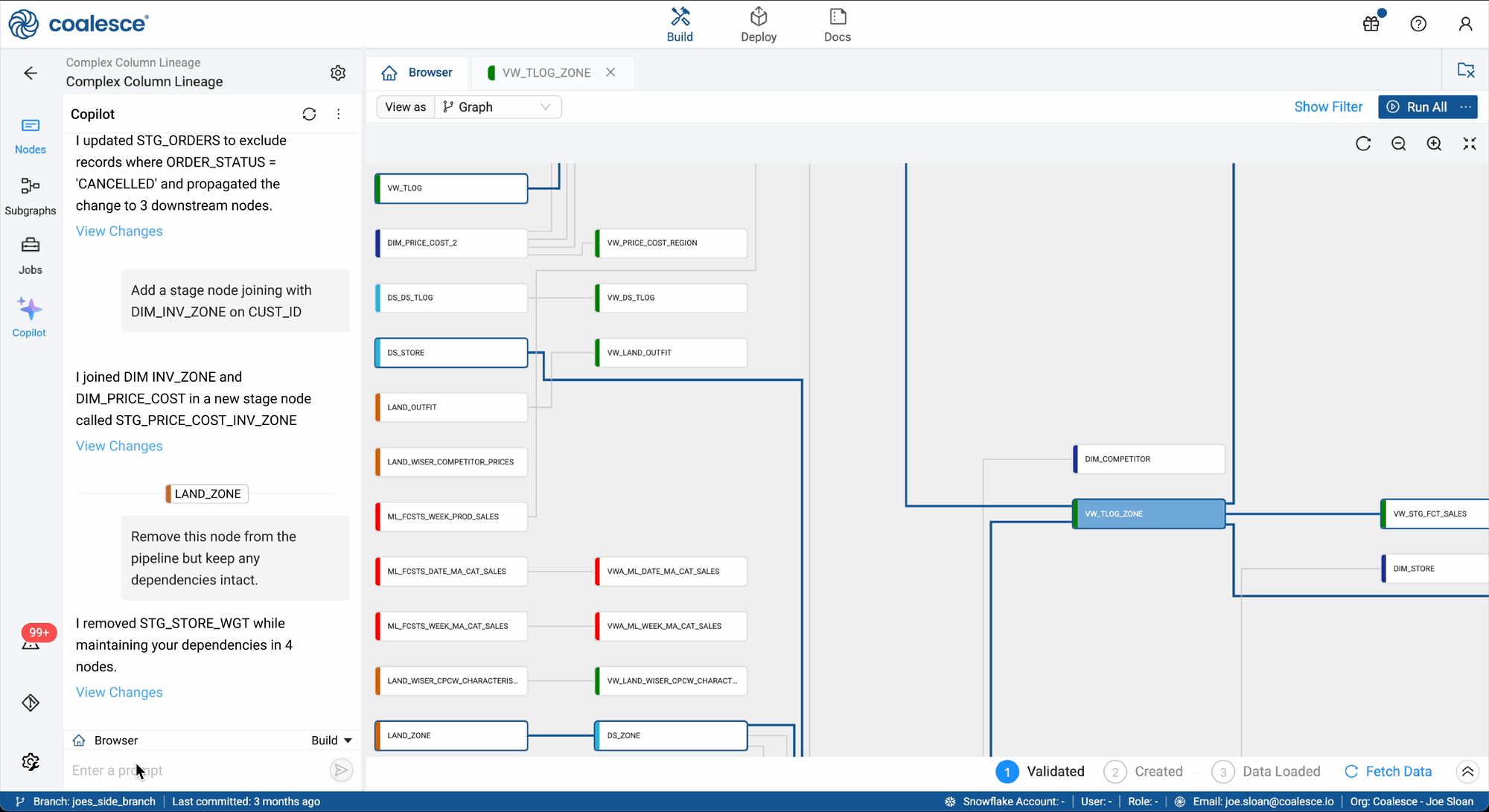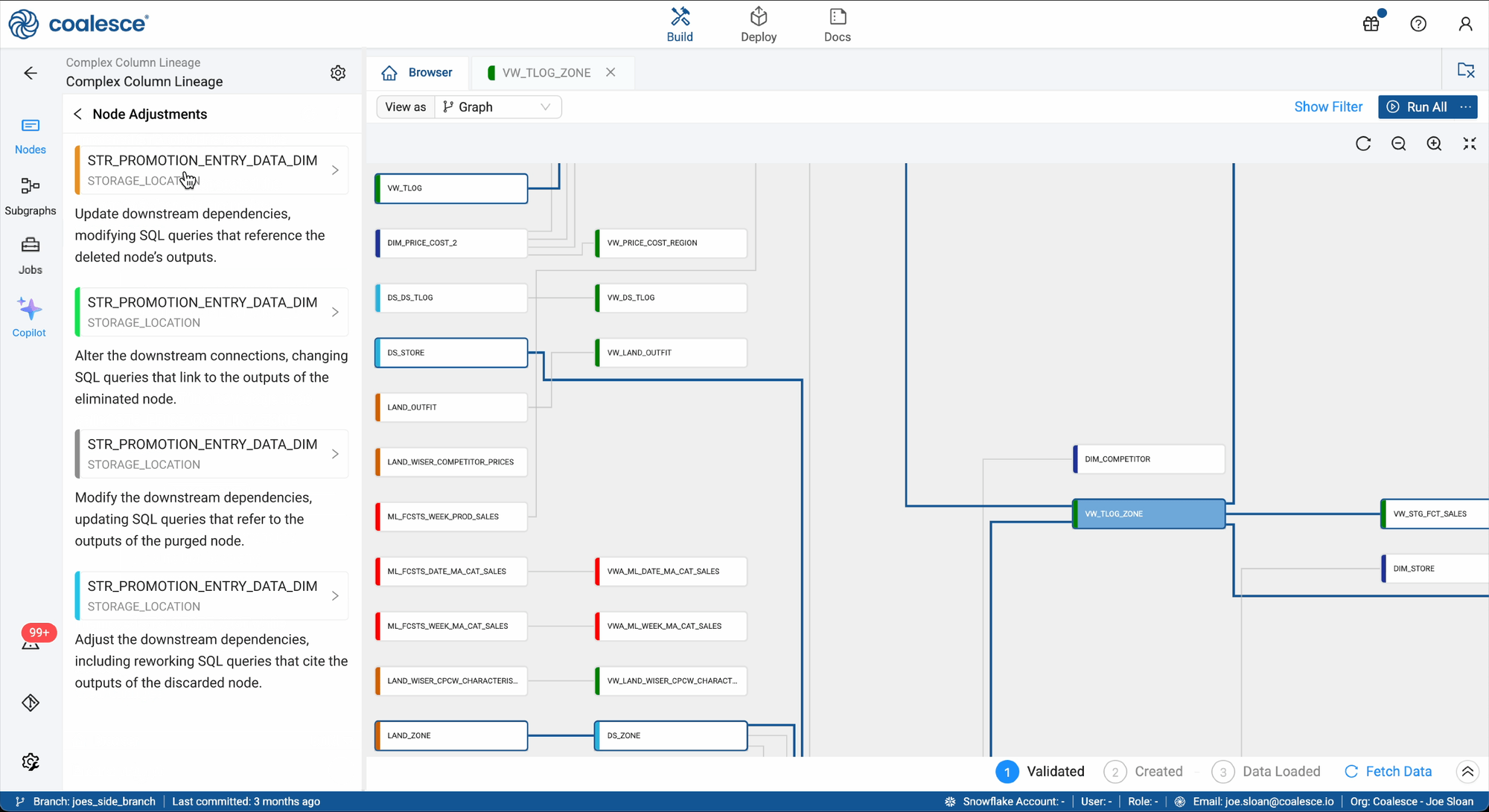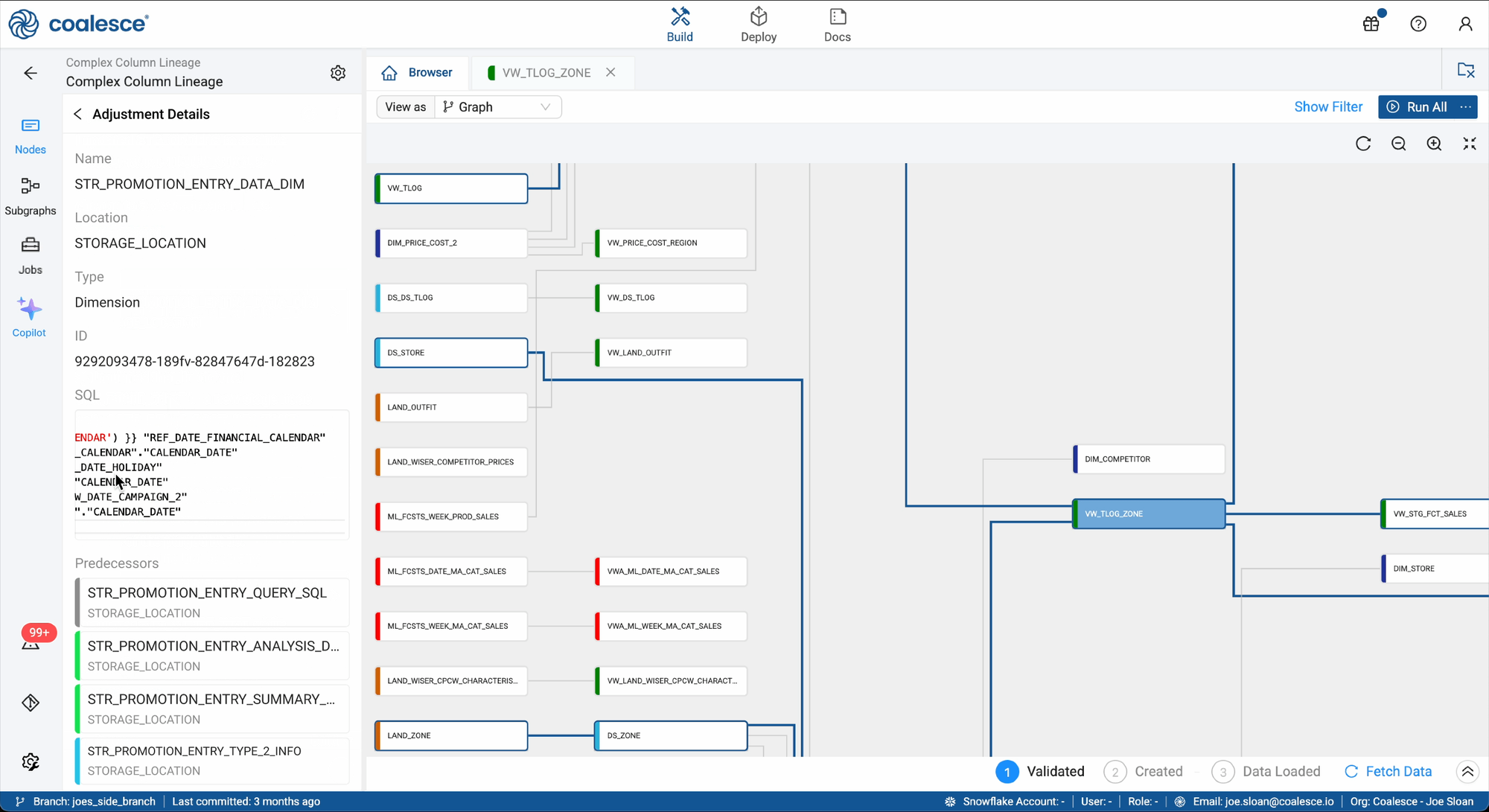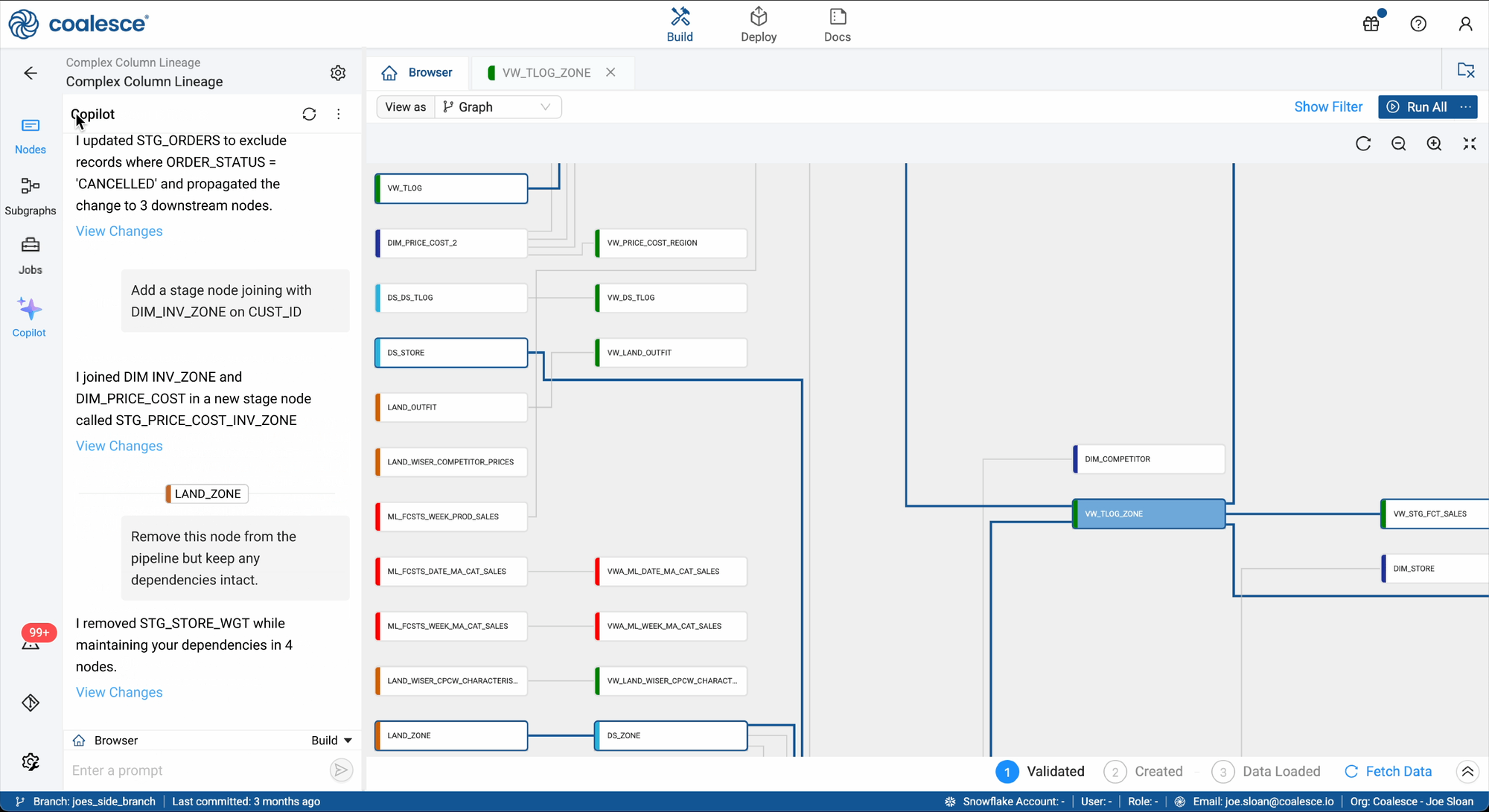
Optimize differently for power users. While less-technical users adopted faster, power users trusted the Copilot more when it minimized explanation and executed tasks using familiar best practices.